
Pixiemint
Overview
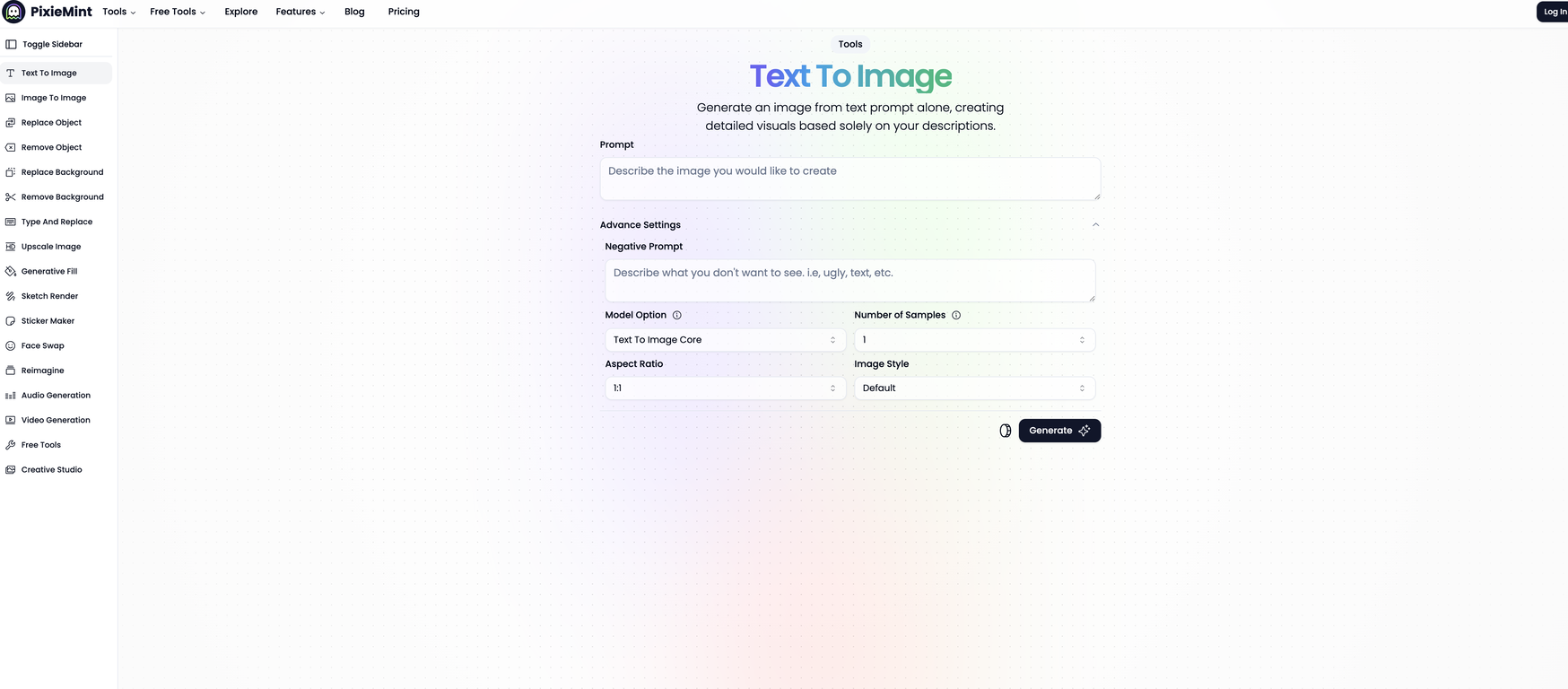
Text To Image is an advanced tool that produces comprehensive visuals solely based on text prompts given by a user. The tool operates by interpreting the inputted text and, in return, generates corresponding imagery that illustrates the given description.
The user is able to dictate the specifics of the image such as the aspect ratio and style through advanced settings, thus allowing a considerable degree of customization.
This tool, therefore, essentially turns linguistic data into a visual format, paving the way for a more intuitive understanding of text-based data. Required inputs include not just the desired image concept described in words, but also other parameters depending on user preference for the output image.
It can be a powerful tool for creatives, designers, and even for AI researchers exploring the conjuncture of natural language understanding and computer vision.
its applications could range from rapid prototyping of design ideas to generating visual aids for better data comprehension.
Releases
Top alternatives
-
Arvoly XSL🙏 117 karmaOct 31, 2023@Photo AIIt's not free, it forces you to input an email before shoving a price tag in your face.
-
-
Freepik helps people to create better designs, faster.
-
-
Six months ago I was building some landing pages and found myself wasting way too much time downloading stock photos, cropping them, resizing, rehosting... the whole thing felt broken. I looked around for a tool that just let me describe the image I wanted and get it in the right format instantly—but nothing really existed. So I built Inliner AI. Now when I need an image, I just write what I want directly into a URL like this: https://img.inliner.ai/my-project/panda-playing-guitar-on-stage_1200x750.png Hit enter and boom Inliner generates an original AI image, intelligently cropped, resized for the web, and served instantly via CDN. Need a quick edit? Just append it to the URL: .../remove-the-guitar_900x750.png No uploads, no UI, no waiting. You can also upload your own products, people, or logos and compose them into generated scenes. For more control, there's a Studio web GUI where you can play with prompts and dimensions and compare variants side by side before committing. Where this gets really powerful is when you show your LLM how to use these URLs. Once it knows the pattern like: https://img.inliner.ai/my-project/xxx-yyy-zzz.png It can generate, tweak, and iterate on image assets dynamically, right inside your prompts or your code. Everything stays self contained in the link. We also include copy/pasteable instructions for Claude, GPT, Cursor, and more so you can wire this up in minutes. If you're building a product, designing a page, or just prototyping something new try it out and let me know what you think!










