Lexi
 AI API proxy — you save first, then we earn. One URL
AI API proxy — you save first, then we earn. One URL
Inputs:
Outputs:
AI API proxy — you save first, then we earn. One URL
Featured alternatives
 APIXO
APIXO
 Velma Transcribe by Modulate
Velma Transcribe by Modulate
146
360
Overview
Lexi is an AI API proxy that sits between your application and the AI providers you already use. It restructures conversation context before each API call — fewer input tokens sent to the model, same response back. You keep the savings.One URL change. That's the integration. Swap your OpenAI or Anthropic base URL for api.lexisaas.com. Streaming, tool calls, function calling, structured output — everything passes through unchanged. Your provider API keys are forwarded directly to OpenAI, Anthropic, or Google on each request and are never stored or logged by Lexi.
HOW BILLING WORKS
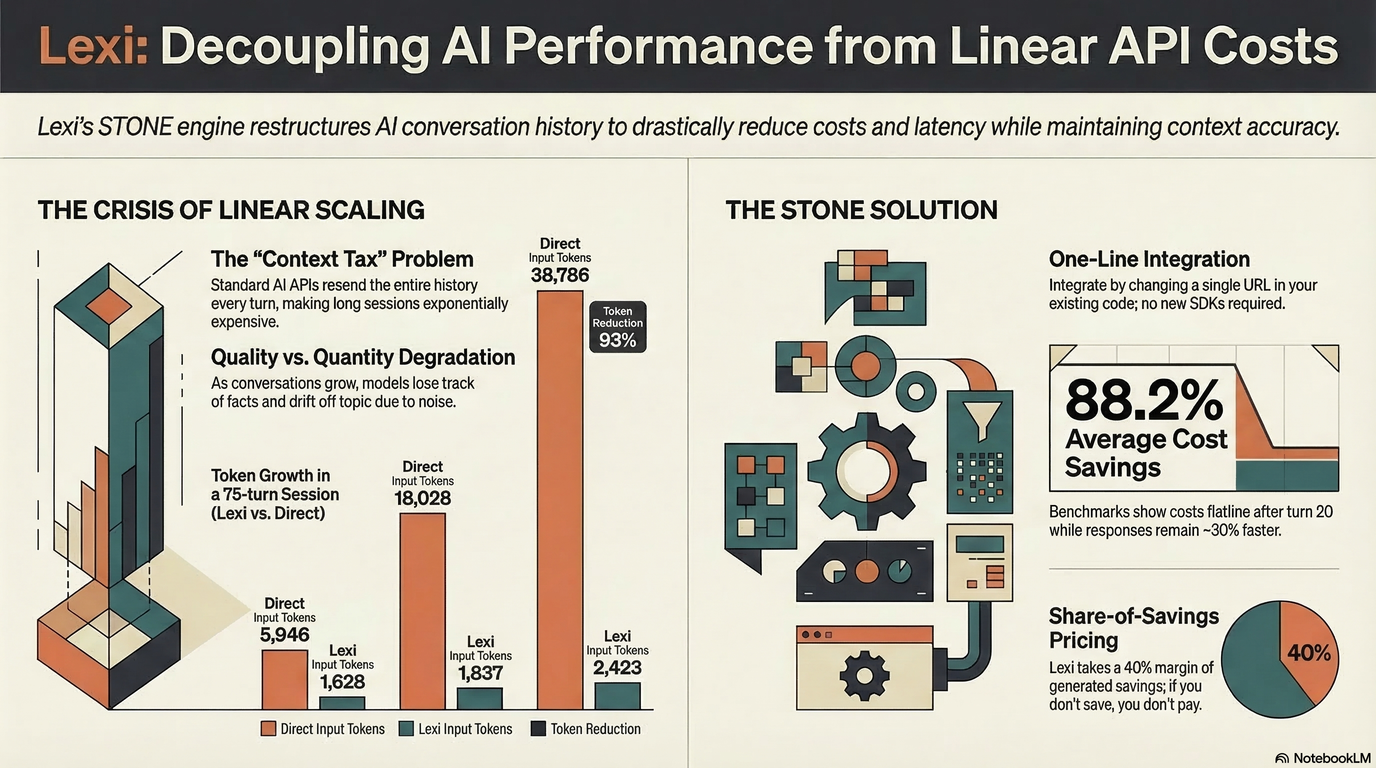
Lexi uses share-of-savings pricing. Your provider charges you less because Lexi sent fewer tokens. Lexi takes 40% of the difference — the savings it generated. The other 60% is yours. If a request produces no savings, there's no Lexi fee. You cannot pay more than going direct.
Every API response includes HTTP headers showing the exact cost breakdown: what you saved, what Lexi earned, and your remaining balance. No estimates, no end-of-month surprises.
WHAT STONE DOES
STONE (Semantic Token Optimization and Natural Encoding) is the engine behind Lexi. Turn 1 passes through unchanged — zero overhead. From turn 2 onward, STONE restructures the conversation history into a bounded form. The payload sent to the AI model stays roughly constant whether you're on turn 5 or turn 75. Cost flatlines instead of growing linearly.
Critical information survives: numbers, dates, decisions, version strings, port numbers, metrics, and named entities are pinned into a permanent anchor. Fact corrections propagate — say "actually it's port 8080, not 5432" and the update sticks.
RECALL SYSTEM
Most AI conversations degrade because the model loses track of what was said 20 or 30 turns ago. Lexi solves this. Every message is permanently archived with AES-256-GCM encryption. When earlier context becomes relevant again, a three-tier recall system retrieves the original content, extracts exactly what the model needs for the current question, and injects it into the request.
This isn't generic retrieval — it's query-conditioned. Ask "what port did we settle on?" and Lexi surfaces the specific decision, not a summary of the entire conversation.
The system also learns from use. After every response, Lexi scores what it recalled against what the model actually used. Strategies that produce useful context get reinforced. The system gets sharper over time.
BENCHMARK RESULTS
In a blind-judged benchmark across a 75-turn conversation covering 7 different topics (project planning, database design, infrastructure, security, debugging, marketing, sprint planning), Lexi delivered:
— 91.6% token savings (1.6M tokens reduced to 136K)
— 88% cost reduction ($0.52 vs $4.37 on GPT-4o)
— 30% lower latency (fewer tokens = faster responses)
— 8.4/10 factual accuracy vs 9.0/10 for full context (0.6-point gap)
— Facts from turn 3 correctly recalled at turn 70+
The benchmark was run 4 times to verify reproducibility. The accuracy gap is in response detail and structure, not factual correctness — Lexi matches full-context on the facts but produces more concise responses.
28 models across 6 providers: OpenAI (GPT-5, GPT-4o, o3, and more), Anthropic (Claude Opus, Sonnet, Haiku), Google (Gemini 3 Pro, Flash), xAI (Grok 4, Grok 3), DeepSeek (V3.2, R1), and Meta (Llama 4).
$10 free credit on signup. No credit card required. Built in Norway by LexiCo AS.
Key Features
- Developer Tools
- Ai Infrastructure
- Llm Operations
Show more
Releases
Get notified when a new version of Lexi is released
Notify me
March 10, 2026

Julian
Initial release of Lexi.
Author

Pricing
Pricing model
Freemium
Paid options from
Free tier available
Billing frequency
Pay-as-you-go
Keeping you safe
Good to know
Related topics
#509
 3
3






How would you rate Lexi?
Help other people by letting them know if this AI was useful.